{kind=link}
I am currently a Ph.D. student (since Fall 2023) in the Department of Electrical and Computer Engineering (ECE, formerly EEE) at The University of Hong Kong (HKU) .
.
Prior to joining HKU, I received my M.S. degree in Big Data Engineering from the Department of Automation and Shenzhen International Graduate School at Tsinghua University (THU) , and my B.S. degree in Electronic and Information Engineering from Nanjing University of Science and Technology (NJUST)
, and my B.S. degree in Electronic and Information Engineering from Nanjing University of Science and Technology (NJUST) .
.
I am fortunate to be advised by Yifan (Evan) Peng & Jia Pan @ HKU.
My research interests encompass Computer Vision (3D/4D), Computer Graphics (Rendering), VR/AR/MR, and Holographic Imaging/Display.
📊 Research Impact: Citations153
📄 CV: English PDF
我目前是香港大学(HKU)电机与计算机工程系(ECE,原 EEE)博士研究生,于 2023 年秋季入学。
在加入港大之前,我于清华大学(THU)自动化系与深圳国际研究生院获得大数据工程硕士学位,并于南京理工大学(NJUST)获得电子信息工程学士学位。
目前我在港大,博士导师为 Yifan (Evan) Peng & Jia Pan @ HKU。
我的研究兴趣包括计算机视觉(3D/4D)、计算机图形学(渲染)、VR/AR/MR,以及计算成像与全息显示。
📊 学术影响力: Citations153
📄 简历: 中文 PDF
🔬 Research Focus🔬 研究方向
My research sits at the intersection of Computer Vision, Computer Graphics, and Artificial Intelligence. I study how to reconstruct, render, generate, and reason about dynamic 3D/4D worlds, with an emphasis on scalable scene representations and physically grounded visual intelligence.
我的研究位于计算机视觉、计算机图形学与人工智能的交叉领域,关注动态 3D/4D 世界的重建、渲染、生成与理解,尤其强调可扩展场景表示与物理一致的视觉智能。
3D/4D World Modeling
NeRF, 3D Gaussian Splatting, stereo, depth, and correspondence methods for reconstructing geometry, appearance, motion, and view synthesis.
Generative Rendering & Simulation
Physically grounded rendering, event-camera simulation, 3D garment modeling, and visual generation for fast, dynamic, and controllable scenes.
Multimodal Visual Intelligence
Vision-language-action reasoning, embodied navigation, world models, and computational imaging systems that connect perception with interaction.
3D/4D 世界建模
研究 NeRF、3D Gaussian Splatting、立体匹配、深度估计与图像对应,用于重建几何、外观、运动与新视角合成。
生成式渲染与仿真
面向快速动态场景的物理一致渲染、事件相机仿真、三维服装建模与可控视觉生成。
多模态视觉智能
探索视觉-语言-动作推理、具身导航、世界模型与计算成像系统,连接视觉感知与交互式智能。
🔥 News🔥 新闻动态
- 2026.06: 🏆 One paper on Fast Motion Reconstruction (ERF-GS) is accepted to Computational Visual Media (CVMJ)!
- 2026.05: 🏆 One paper on Event Camera Rendering (EventTracer) is accepted to IEEE Transactions on Visualization and Computer Graphics (TVCG)!
- 2026.04: 🏆 One paper on 3D Garment Modeling (PatternGSL) is accepted to SIGGRAPH 2026!
- 2026.05: 📄 One paper on Zero-Shot Object Navigation (ConsistNav) is released on arXiv! Closing the action consistency gap with semantic executive control.
- 2026.04: 📄 One paper on AR-assisted dental implant surgery is published in Journal of the Society for Information Display (JSID) 2026!
- 2026.03: 🏆 One paper on Stereo Matching Generalization is accepted to 3DV 2026! Structure-grounded training strategies for robust stereo matching.
- 2026.03: 📄 One paper on Panoramic Instance Segmentation (SAP) is released on arXiv! Segment Any 4K Panorama for high-resolution 360° scenes.
- 2026.03: 🎓 Serving as Program Committee Member for 34th ACM Multimedia (ACMMM) 2026!
- 2025.07: 🏆 One paper on 4D Gaussian Splatting is accepted to ISMAR 2025! This work focuses on enhanced velocity field modeling for video reconstruction.
- 2025.07: 🏆 One paper on Physically Correct Video Generation is accepted to ICCV 2025! Material-agnostic system identification from videos.
- 2026.06: 🏆 一篇关于快速运动重建的论文(ERF-GS)被 Computational Visual Media (CVMJ) 接收!
- 2026.05: 🏆 一篇关于事件相机渲染的论文(EventTracer)被 IEEE Transactions on Visualization and Computer Graphics (TVCG) 接收!
- 2026.04: 🏆 一篇关于三维服装建模的论文(PatternGSL)被 SIGGRAPH 2026 接收!
- 2026.05: 📄 一篇关于零样本目标导航的论文(ConsistNav)已发布于 arXiv!聚焦通过语义执行控制弥合动作一致性鸿沟。
- 2026.04: 📄 一篇关于增强现实辅助牙种植导航的论文发表于 Journal of the Society for Information Display (JSID) 2026!
- 2026.03: 🏆 一篇关于立体匹配泛化的论文被 3DV 2026 接收!提出面向稳健立体匹配的结构先验训练策略。
- 2026.03: 📄 全景实例分割论文 SAP 已发布于 arXiv!工作聚焦高分辨率 360° 场景的
Segment Any 4K Panorama。 - 2026.03: 🎓 担任 第 34 届 ACM Multimedia(ACMMM)2026 程序委员会成员!
- 2025.07: 🏆 一篇关于 4D Gaussian Splatting 的论文被 ISMAR 2025 接收!该工作聚焦视频重建中的增强速度场建模。
- 2025.07: 🏆 一篇关于物理正确视频生成的论文被 ICCV 2025 接收!研究从视频中进行材料无关系统辨识。
📝 Publications📝 论文发表
🎯 Selected Publications (* indicates equal contribution)🎯 代表性论文(* 表示共同一作)
2026
PatternGSL: A Structured Specification Language for Template-Free and Simulation-Ready 3D Garments
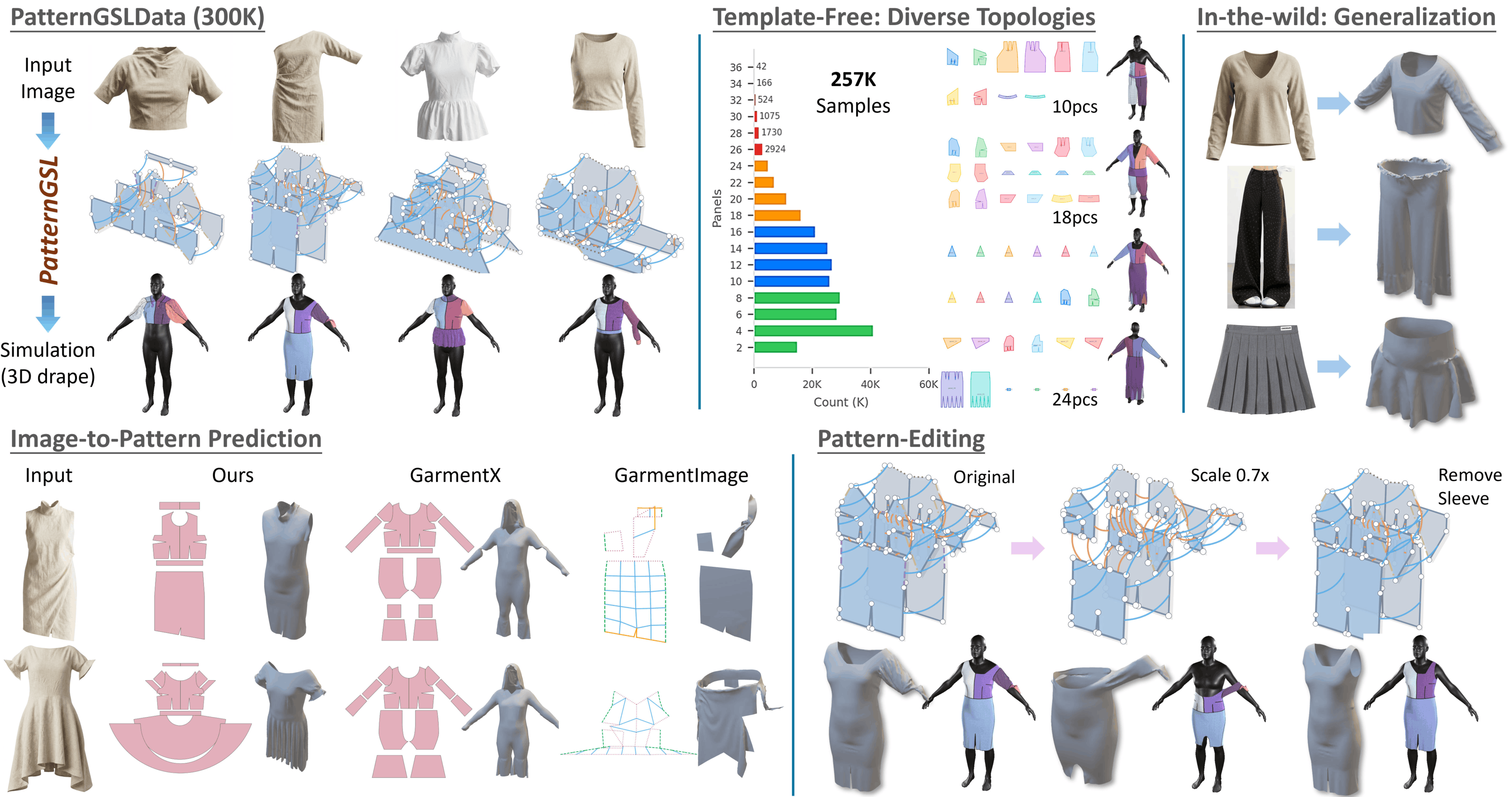
Zhenyang Li*, Lutao Jiang*, Yizhou Zhao, Weikai Chen, Ying-Cong Chen, Xin Wang, Yifan Peng.
EventTracer: Fast Path Tracing-based Event Stream Rendering

Zhenyang Li*, Xiaoyang Bai*, Jinfan Lu, Pengfei Shen, Yifan Peng.
Accepted to IEEE Transactions on Visualization and Computer Graphics (TVCG). Project / arXiv / Hugging FaceERF-GS: Reconstructing Fast Motion from Disjoint Event-RGB Viewpoints
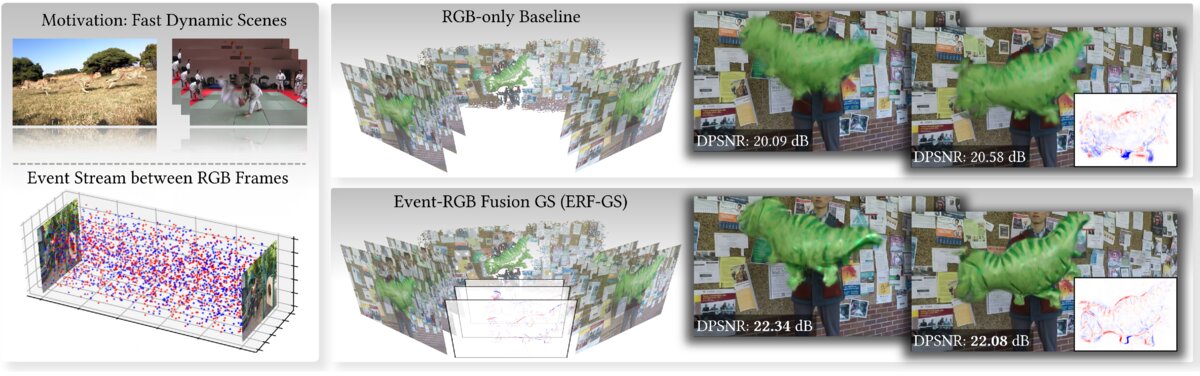
Xiaoyang Bai*, Zhenyang Li*, Weiwei Xu, Edmund Y. Lam, Yifan Peng.
Accepted to Computational Visual Media (CVMJ).Structure-grounded Training Strategies Aid Generalization in Stereo Matching

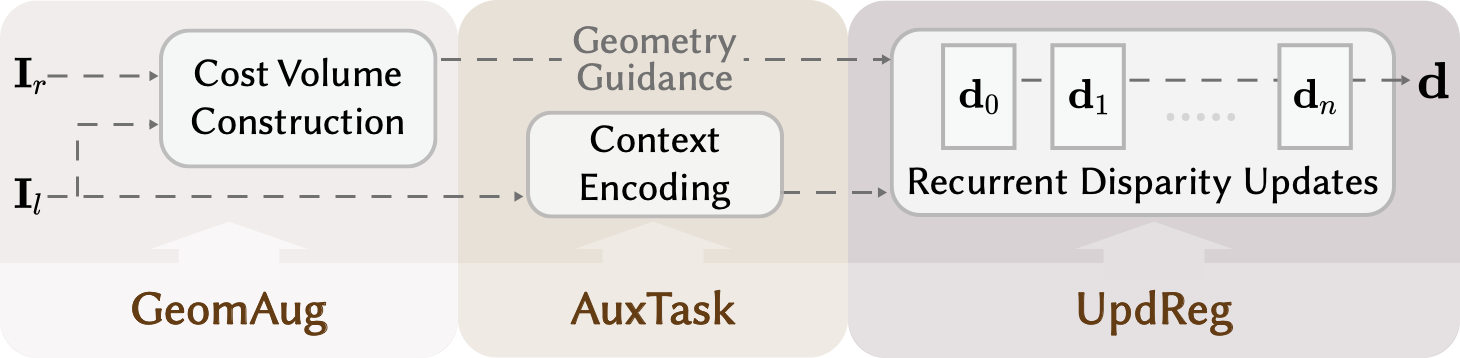

Liangxun Ou, Yuhui Liu, Zhenyang Li, Xiaoyang Bai, Yifan Peng.
-
Augmented Reality Integration Improves Ergonomics in Dynamic Navigation for Dental Implant Surgery Pui Hang Leung, Feng Wang, Zhenyang Li, Zongqi He, Yifan Peng, Wei-fa Yang.
ConsistNav: Closing the Action Consistency Gap in Zero-Shot Object Navigation with Semantic Executive Control
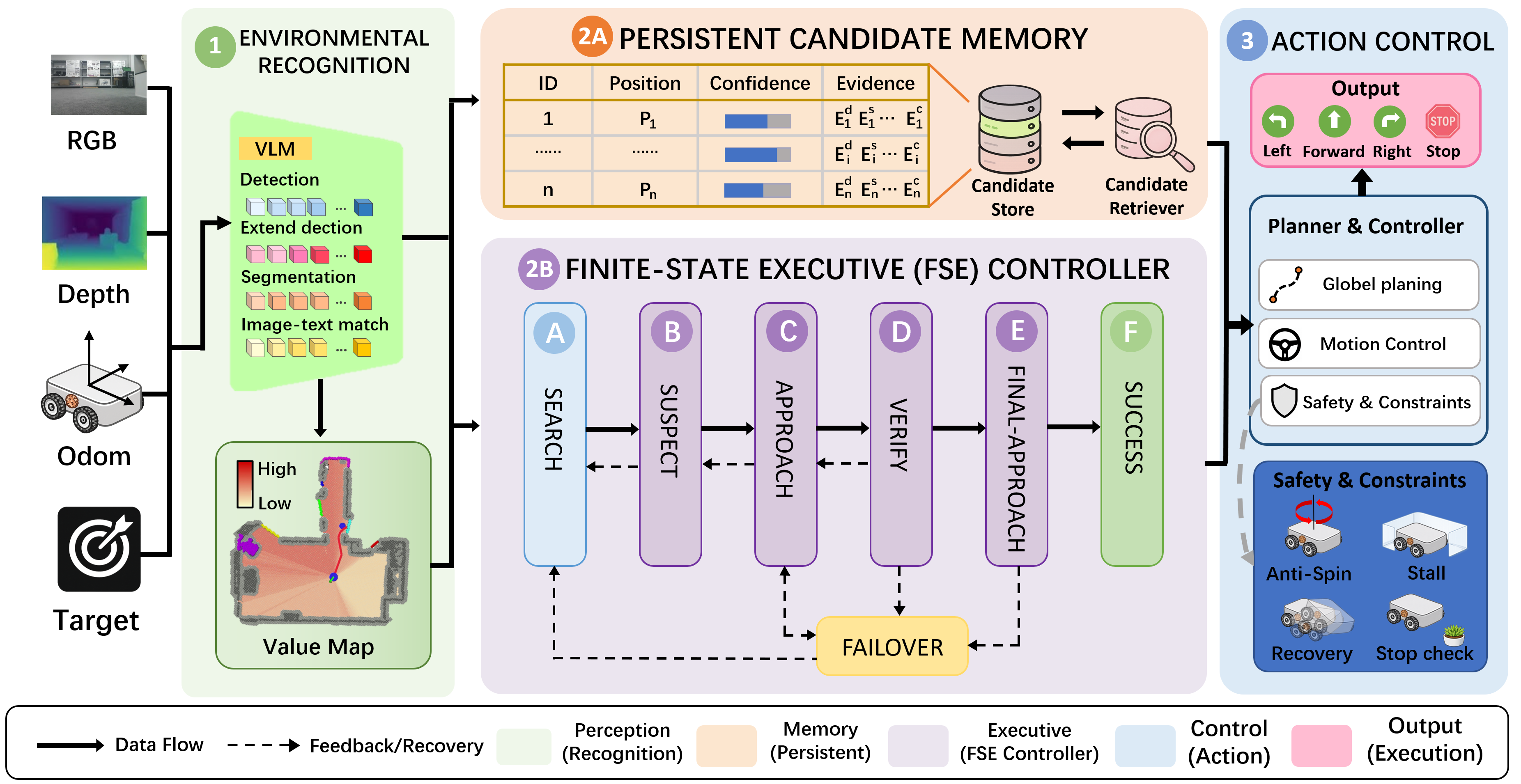
Haosen Wang*, Zhenyang Li*, Yinqiang Zhang, Zongqi He, Lutao Jiang, Kai Li, Yizhou Zhao, Liaoyuan Fan, Wenjian Hou, Tingbang Liang, Yibin Wen, Defeng Gu.
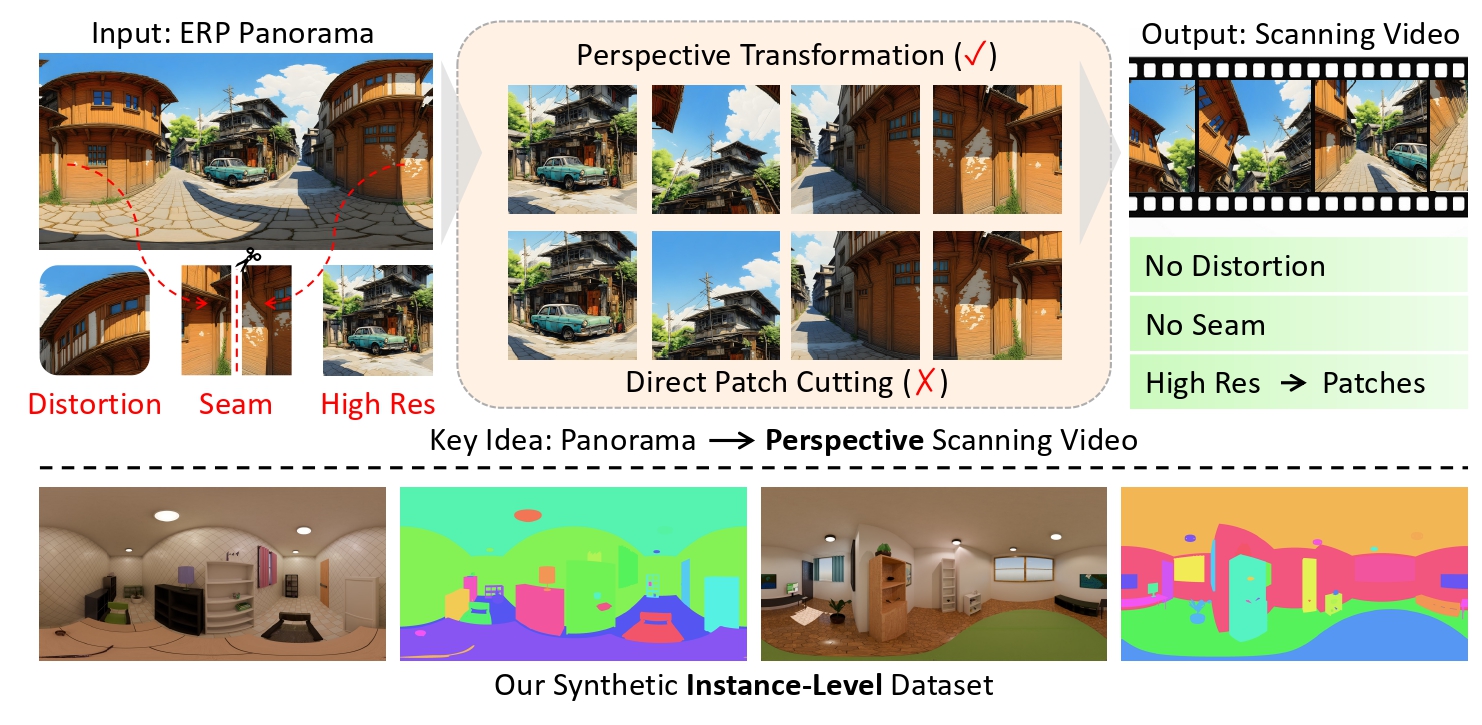
Lutao Jiang, Zidong Cao, Weikai Chen, Xu Zheng, Yuanhuiyi Lyu, Zhenyang Li, Zeyu Hu, Yingda Yin, Keyang Luo, Runze Zhang, Kai Yan, Shengju Qian, Haidi Fan, Yifan Peng, Xin Wang, Hui Xiong, Ying-Cong Chen.
2025
Toward Material-Agnostic System Identification from Videos

Yizhou Zhao, Haoyu Chen, Chunjiang Liu, Zhenyang Li, Charles Herrmann, Junhwa Hur, Yinxiao Li, Ming-Hsuan Yang, Bhiksha Raj, Min Xu.
Enhanced Velocity Field Modeling for Gaussian Video Reconstruction

Zhenyang Li*, Xiaoyang Bai*, Tongchen Zhang, Pengfei Shen, Weiwei Xu, Yifan Peng.
ORBIT: Overlapping Region-Based Image Feature Matching Technique (Preprint Coming Soon)
Qi Luo*, Zhenyang Li*, Linsong Xue, Haojie Wu, Yifan Peng, Kai Zhang.
2024
3D-HoloNet: Fast, unfiltered, 3D hologram generation with camera-calibrated network learning

Wenbin Zhou, Feifan Qu, Xiangyu Meng, Zhenyang Li, Yifan Peng
CryoSAM: Training-free CryoET Tomogram Segmentation with Foundation Models

Yizhou Zhao, Hengwei Bian, Michael Mu, Mostofa R. Uddin, Zhenyang Li, Xiang Li, Tianyang Wang, Min Xu.
Point Resampling and Ray Transformation Aid to Editable NeRF Models

Zhenyang Li*, Zilong Chen*, Feifan Qu, Mingqing Wang, Yizhou Zhao, Kai Zhang, Yifan Peng.
2023
Breaking Filter Bubble: A Reinforcement Learning Framework of Controllable Recommender System

Zhenyang Li*, Yancheng Dong*, Chen Gao, Yizhou Zhao, Dong Li, Jianye Hao, Kai Zhang, Yong Li, Zhi Wang.
Unsupervised Anomaly Detection with Local-Sensitive VQVAE and Global-Sensitive Transformers Mingqing Wang, Jiawei Li, Zhenyang Li, Chengxiao Luo, Bin Chen, Shu-Tao Xia, Zhi Wang.
2022
Alignment-guided Temporal Attention for Video Action Recognition

Yizhou Zhao*, Zhenyang Li*, Xun Guo, Yan Lu.
Adaptive Range guided Multi-view Depth Estimation with Normal Ranking Loss

Yikang Ding*, Zhenyang Li*, Dihe Huang, Kai Zhang, Zhiheng Li, Wensen Feng.
Enhancing multi-view stereo with contrastive matching and weighted focal loss

Yikang Ding*, Zhenyang Li*, Dihe Huang, Zhiheng Li, Kai Zhang.
🎖 Honors and Awards🎖 荣誉与奖励
🏆 Competitions
-
2023.12 Champion 🥇, Guangdong-Hong Kong-Macao Greater Bay Area (Huangpu) International Algorithm Case Competition
Topic: Three-dimensional reconstruction of objects using neural implicit representation -
2020.04 Top 7/256 🥈, High-energy particle collision classification challenge, Beindata
-
2019.05 Second Prize 🥉, American College Student Mathematical Modeling Contest (MCM)
💰 Scholarships & Academic Honors
- 2017 TE Connectivity Scholarship (Top 1/600), Beijing SMC Education Foundation Outstanding Scholarship Special Award (Top 1/600), Second Prize in National Mathematics Competition for College Students
🏆 竞赛获奖
-
2023.12 冠军 🥇,粤港澳大湾区(黄埔)国际算法算例大赛
赛题:基于神经隐式表示的物体三维重建 -
2020.04 前 7 / 256 🥈,高能粒子碰撞分类挑战赛,Beindata
-
2019.05 二等奖 🥉,美国大学生数学建模竞赛(MCM)
💰 奖学金与学术荣誉
- 2017 TE Connectivity Scholarship(Top 1/600)、北京晟铭创科教育基金会优秀学生奖学金特等奖(Top 1/600)、全国大学生数学竞赛二等奖
📖 Education📖 教育经历
-
🎓 Ph.D. in Electrical and Computer Engineering (formerly EEE) | 2023.09 - Present
The University of Hong Kong (HKU)
Advisor: Yifan (Evan) Peng & Jia Pan @ HKU -
🎓 M.S. in Big Data Engineering | 2020.09 - 2023.07
Tsinghua University (THU)
Department of Automation & Shenzhen International Graduate School
Advisor: Prof. Kai Zhang -
🎓 B.S. in Electronic and Information Engineering | 2016.09 - 2020.07
Nanjing University of Science and Technology (NJUST)
School of Electronic and Optical Engineering
-
🎓 电机与电子工程博士(原 EEE) | 2023.09 - 至今
香港大学(HKU)
导师:Yifan (Evan) Peng & Jia Pan @ HKU -
🎓 大数据工程硕士 | 2020.09 - 2023.07
清华大学(THU)
自动化系、深圳国际研究生院
导师:Kai Zhang 教授 -
🎓 电子信息工程学士 | 2016.09 - 2020.07
南京理工大学(NJUST)
电子与光学工程学院
💻 Internships💻 实习经历
-
🏢 Research Intern | Oct. 2025 - Present
Tencent LIGHTSPEED STUDIOS, Shenzhen, Guangdong, China
Research Focus: Multimodal & 3D Content Generation and Simulation -
🏢 Research Intern | Jul. 2022 - Nov. 2022
Megvii Technology Limited (Face++), Beijing, China
Research Focus: Visual Odometry, NeRF, Multi-View Stereo (MVS), Feature Matching -
🏢 Research Intern | Nov. 2021 - May. 2022
Microsoft Research Asia (MSRA), Beijing, China
Research Focus: Video Understanding, Learning-based Computer Vision -
🏢 Artificial Intelligence Researcher | Mar. 2021 - Sep. 2021
Huawei Technologies Co., Ltd., Shenzhen, Guangdong, China
Research Focus: 3D Reconstruction, Visual Localization
-
🏢 研究实习生 | 2025.10 - 至今
Tencent LIGHTSPEED STUDIOS,中国广东深圳
研究方向:多模态与 3D 内容生成及仿真 -
🏢 研究实习生 | 2022.07 - 2022.11
Megvii Technology Limited (Face++),中国北京
研究方向:视觉里程计、NeRF、多视图立体(MVS)、特征匹配 -
🏢 研究实习生 | 2021.11 - 2022.05
Microsoft Research Asia (MSRA),中国北京
研究方向:视频理解、学习式计算机视觉 -
🏢 人工智能研究员 | 2021.03 - 2021.09
Huawei Technologies Co., Ltd.,中国广东深圳
研究方向:三维重建、视觉定位
🧑⚖️ Academic Service🧑⚖️ 学术服务
Program Committee Member
- 34th ACM Multimedia (ACMMM) 2026
Conference Reviewer
2026
- CVPR 2026, ECCV 2026, NeurIPS 2026, BMVC 2026, 3DV 2026, ISMAR 2026
2025
- SIGGRAPH Asia 2025 (XR Track), ICCV 2025, ISMAR 2025
- NeurIPS 2025 (Main + Datasets and Benchmarks), ICML 2025, ICLR 2025
- ACM MM 2025, AISTATS 2025, ACML 2025, 3DV 2025
2024
- NeurIPS 2024
Journal Reviewer
- IEEE Journal of Selected Topics in Signal Processing (J-STSP)
程序委员会成员
- 第 34 届 ACM Multimedia(ACMMM)2026
会议审稿
2026
- CVPR 2026、ECCV 2026、NeurIPS 2026、BMVC 2026、3DV 2026、ISMAR 2026
2025
- SIGGRAPH Asia 2025(XR Track)、ICCV 2025、ISMAR 2025
- NeurIPS 2025(Main + Datasets and Benchmarks)、ICML 2025、ICLR 2025
- ACM MM 2025、AISTATS 2025、ACML 2025、3DV 2025
2024
- NeurIPS 2024
期刊审稿
- IEEE Journal of Selected Topics in Signal Processing(J-STSP)
💬 Invited Talks & Teaching💬 报告与教学
-
🎤 Workshop Organizer & Speaker | Dec. 2025
WeLight Workshop, The University of Hong Kong
Organized by WeLightLab@HKU -
🎤 Guest Lecturer | May 2023
ELEC4544: AI and Deep Learning, The University of Hong Kong
Invited by Dr. Yifan (Evan) Peng
-
🎤 Workshop 组织者与报告人 | 2025.12
WeLight Workshop,香港大学
由 WeLightLab@HKU 组织 -
🎤 特邀讲师 | 2023.05
ELEC4544: AI and Deep Learning,香港大学
由 Yifan(Evan)Peng 博士邀请